Documentation
Setup
Installation
-
nl4dv requires a 64-bit Python 3 environment. Windows users must ensure that Microsoft C++ Build Tools is installed. Mac OS X users must ensure that Xcode is installed.
-
Install using one of the below methods:
-
PyPi.
To download, run
pip install nl4dv==4.1.0 -
A local distributable. Download
nl4dv-4.1.0.tar.gz OR nl4dv-4.1.0.zip
Accordingly, run
ORpip install nl4dv-4.1.0.tar.gz
.pip install nl4dv-4.1.0.zip
Note: We recommend installing NL4DV in a virtual environment as it avoids version conflicts with globally installed packages.
-
Post Installation
-
Instructions for "processing_mode" = "language-model" (v4)
NL4DV requires an API Key to configure the new "processing_mode" = "language-model". Internally, NL4DV utilizes LiteLLM as its LLM gateway, which enables access to a variety of language models. Check the LiteLLM website to know more about the supported models and accordingly generate an API Key for your chosen model.
Instructions for "processing_mode" = "gpt" (v3)
NL4DV requires an OpenAI API key for its "processing_mode" = "gpt". Please refer the OpenAI website to generate an API Key.
Instructions for "processing_mode" = "semantic-parsing" (v1, v2)
-
NL4DV installs nltk by default but requires a few datasets/models/corpora to be separately installed. Please download the popular nltk artifacts using:
python -m nltk.downloader popular -
NL4DV requires a third-party Dependency Parser module to infer tasks. Download and install one of:
-
Stanford CoreNLP (recommended):
-
Download the English model of Stanford CoreNLP version 3.9.2 and copy it to `examples/assets/jars/` or a known location.
-
Download the Stanford Parser version 3.9.2 and after unzipping the folder, copy the `stanford-parser.jar` file to `examples/assets/jars/` or a known location.
Note: This requires JAVA installed and the JAVA_HOME / JAVAHOME environment variables to be set.
-
-
-
Download the Stanford CoreNLPServer, unzip it in a known location, and
cdinto it. -
Start the server using the below command. It will run on http://localhost:9000.
java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -annotators "tokenize,ssplit,pos,lemma,parse,sentiment" -port 9000 -timeout 30000Note: This requires JAVA installed and the JAVA_HOME / JAVAHOME environment variables to be set.
-
-
Spacy :
-
NL4DV installs Spacy by default but requires a model to be separately installed. Install the sample English model using:
python -m spacy download en_core_web_sm -
If you face the urllib3 v2.0 only supports OpenSSL 1.1.1+, currently the 'ssl' module is compiled with LibreSSL 2.8.3 error while installing spacy models, as per this stackoverflow post, perform the following operations until there is a better fix:
pip uninstall urllib3 && pip install 'urllib3<2.0'
-
-
-
Sample Code | v4 ('language-model') | NL4DV-Stylist
import json
from nl4dv import NL4DV
# Your dataset must be hosted on Github for the LLM-based mode to function.
data_url="https://raw.githubusercontent.com/nl4dv/nl4dv/master/examples/assets/data/movies-w-year.csv" #paste your data URL
# Choose your processing mode LLM or parsing. Choose "language-model" for the language-model based mode or "semantic-parsing" for the rules-based mode.
processing_mode="language-model"
# Enter your Language Model configuration
lm_config = {
"model": "gpt-4o", # gpt-4o, gpt-4o-mini
"environ_var_name": "OPENAI_API_KEY",
"api_key": "Your api key",
"api_base": None
}
# Define a query
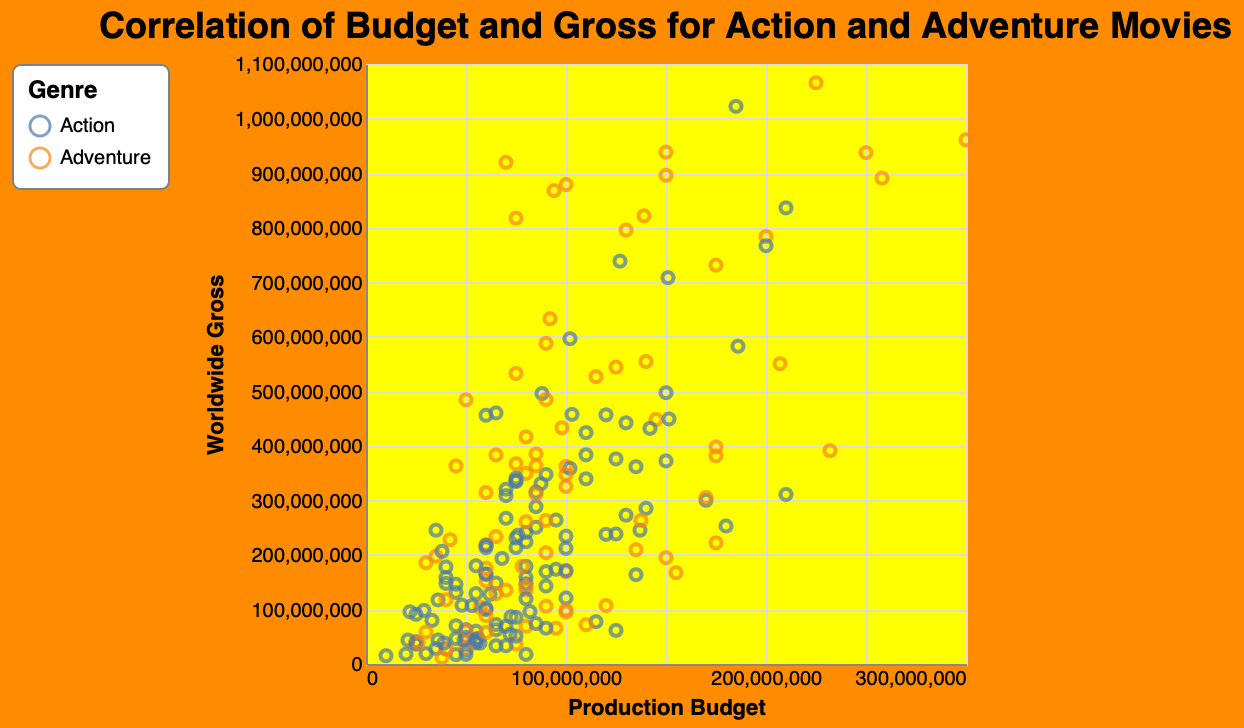
query = "correlate budget and gross for action and adventure movies"
design_config = [{
"type": "image_url",
"image_url": { "url": "https://i.ibb.co/LXk7QMvL/17.png"}, # examples/assets/example-charts/17.png
},{
"type": "text",
"text": " ".join(["Apply this chart's design.", "Remove ticks on either axes."])
},{
"type": "image_url",
"image_url": { "url": "https://i.ibb.co/HTL4HQSP/4.png"}, # examples/assets/example-charts/4.png
},{
"type": "text",
"text": " ".join(["Apply this chart's title's font style and position.", "Apply this chart's legend's style but position it to the left of the chart, not right."])
}]
# Initialize an instance of NL4DV
nl4dv_instance = NL4DV(data_url=data_url, processing_mode=processing_mode, lm_config=lm_config, design_config=design_config)
# Execute the query
output = nl4dv_instance.analyze_query(query)
# Print the output
print(output)
Output
{
"query": "correlate budget and gross for action and adventure movies",
"query_raw": "correlate budget and gross for action and adventure movies",
"dataset": "https://raw.githubusercontent.com/nl4dv/nl4dv/master/examples/assets/data/movies-w-year.csv",
"visList": ["..."],
"attributeMap": {"..."},
"taskMap": {"..."},
"vlSpec": {"..."}, // Vega-Lite specification without any design customizations.
"vlSpec_design": {"..."}, // New in v4. Vega-Lite specification with requested design customizations.
"design_checklist": ["..."], // New in v4.
"design_successlist": ["..."], // New in v4.
"design_failurelist": [] // New in v4.
}
"vlSpec_design" ▸
Note that "vlSpec_design" is a new property in v4 containing a Vega-Lite specification that includes the design customizations requested by the user; the original "vlSpec" property continues to exist with the Vega-Lite specification without any design customizations (i.e., with the default designs).
{
"$schema": "https://vega.github.io/schema/vega-lite/v6.json",
"data": {
"url": "https://raw.githubusercontent.com/nl4dv/nl4dv/master/examples/assets/data/movies-w-year.csv"
},
"transform": [
{
"filter": {
"field": "Genre",
"oneOf": ["Action", "Adventure"]
}
}
],
"mark": "point",
"encoding": {
"x": {
"field": "Production Budget",
"type": "quantitative",
"axis": {
"ticks": false
}
},
"y": {
"field": "Worldwide Gross",
"type": "quantitative",
"axis": {
"ticks": false
}
},
"color": {
"field": "Genre",
"type": "nominal",
"legend": {
"padding": 8
}
}
},
"config": {
"background": "#ff8c00",
"view": {
"fill": "#ffff00"
},
"legend": {
"orient": "left",
"fillColor": "white",
"strokeColor": "gray",
"cornerRadius": 4,
"titleFontSize": 12
}
},
"title": {
"text": "Correlation of Budget and Gross for Action and Adventure Movies",
"fontSize": 18,
"fontWeight": "bold",
"anchor": "middle",
"align": "center"
}
}"design_checklist" ▸
[
{
"type": "chart",
"name": "chart 1",
"content": [
"Apply this chart's design.",
"Remove ticks on either axes."
]
},
{
"type": "chart",
"name": "chart 2",
"content": [
"Apply this chart's title's font style and position.",
"Apply this chart's legend's style but position it to the left of the chart."
]
}
]"design_successlist"▸
[
{
"type": "chart",
"name": "chart 1",
"content": [
"Used background color.",
"Used mark styles."
]
},
{
"type": "chart",
"name": "chart 2",
"content": [
"Used title font style and position.",
"Used legend style and positioned it to the left."
]
}
]"design_failurelist" ▸
[]Visualization (when the Vega-Lite spec is rendered) ▸
Sample Code | v3 ('gpt') | NL4DV-LLM
from nl4dv import NL4DV
#Your dataset must be hosted on Github for the LLM-based mode to function.
data_url="https://raw.githubusercontent.com/nl4dv/nl4dv/master/examples/assets/data/movies-w-year.csv" #paste your data URL
# Choose your processing mode LLM or parsing. Choose "gpt" for the LLM-based mode or "semantic-parsing" for the rules-based mode.
processing_mode="gpt"
#Enter your OpenAI key
gpt_api_key="[OpenAI KEY HERE]"
# Initialize an instance of NL4DV
nl4dv_instance = NL4DV(data_url=data_url, processing_mode=processing_mode, gpt_api_key=gpt_api_key)
# Define a query
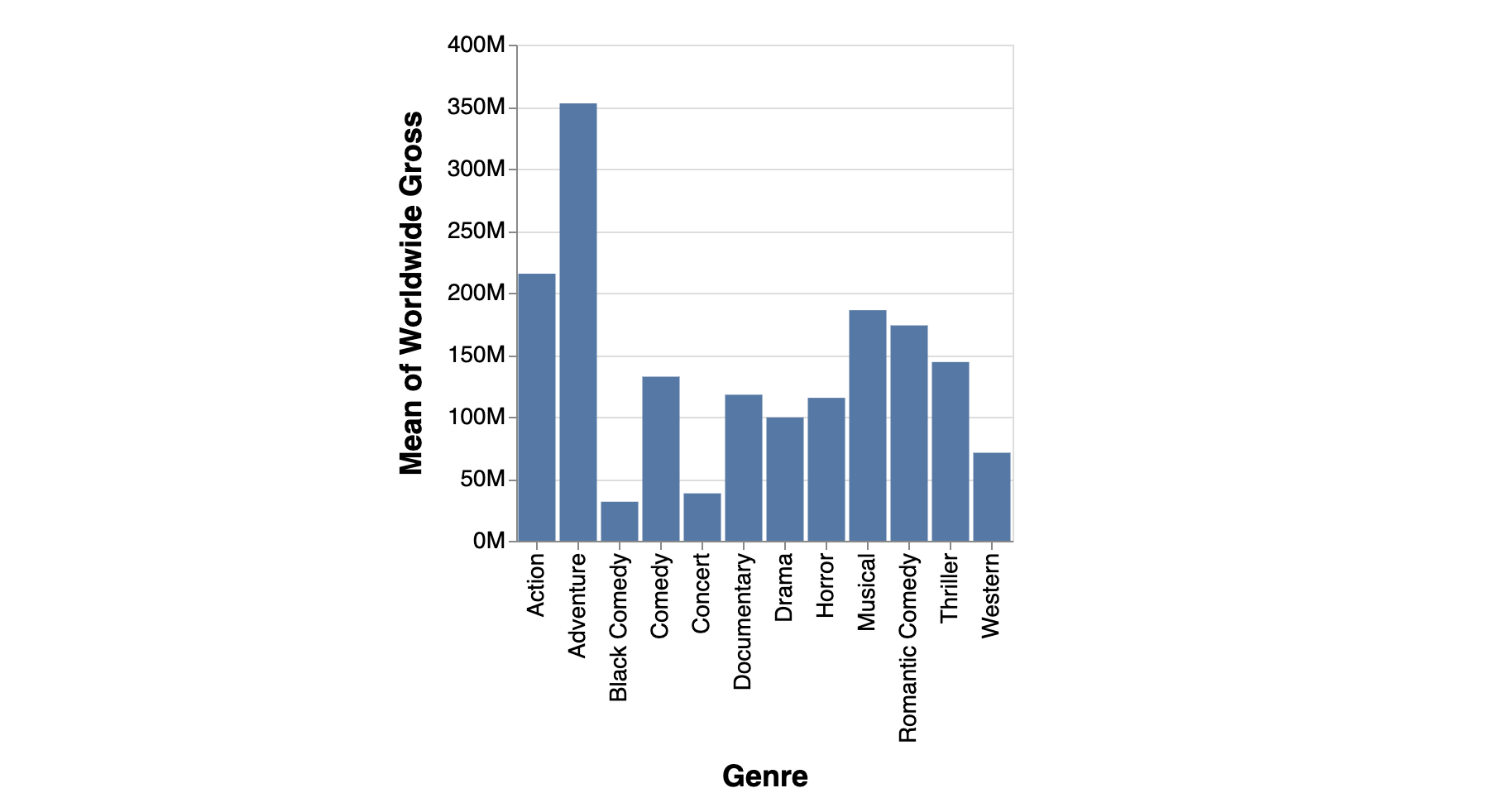
query = "create a barchart showing average gross across genres"
# Execute the query
output = nl4dv_instance.analyze_query(query)
# Print the output
print(output)Output
{
"query": "create a barchart showing average gross across genres",
"dataset": "https://raw.githubusercontent.com/nl4dv/nl4dv/master/examples/assets/data/cars-w-year.csv",
"attributeMap": {"..."},
"taskMap": {"..."},
"visList": ["..."],
"followUpQuery": false,
"contextObj": null
}"attributeMap" ▸
{
"Worldwide Gross": {
"name": "Worldwide Gross",
"queryPhrase": ["gross"],
"inferenceType": "explicit",
"isAmbiguous": false,
"ambiguity": []
},
"Genre": {
"name": "Genre",
"queryPhrase": ["genres"],
"inferenceType": "explicit",
"isAmbiguous": false,
"ambiguity": []
}
}"taskMap" ▸
{
"derived_value": [
{
"task": "derived_value",
"queryPhrase": "average",
"operator": "AVG",
"values": [],
"attributes": [
"Worldwide Gross"
],
"inferenceType": "explicit"
}
]
}"visList"▸
[
{
"attributes": [
"Worldwide Gross",
"Genre"
],
"queryPhrase": "barchart",
"visType": "barchart",
"tasks": [
"derived_value"
],
"inferenceType": "explicit",
"vlSpec": {
"$schema": "https://vega.github.io/schema/vega-lite/v6.json",
"mark": {
"type": "bar",
"tooltip": true
},
"encoding": {
"y": {
"field": "Worldwide Gross",
"type": "quantitative",
"aggregate": "mean",
"axis": {
"format": "s"
}
},
"x": {
"field": "Genre",
"type": "nominal",
"aggregate": null
}
},
"transform": [],
"data": {
"url": "https://raw.githubusercontent.com/nl4dv/nl4dv/master/examples/assets/data/cars-w-year.csv",
"format": {
"type": "csv"
}
}
}
}
]Visualization (when the Vega-Lite spec is rendered) ▸
Sample Code | v2 ('semantic-parsing') | Multi-Turn Dialogs

Sample Code | v1 ('semantic-parsing') | Single-Turn Utterances
from nl4dv import NL4DV
import os
# Initialize an instance of NL4DV
# ToDo: verify the path to the source data file. modify accordingly.
nl4dv_instance = NL4DV(data_url = os.path.join(".", "examples", "assets", "data", "movies-w-year.csv"))
# using Stanford Core NLP
# ToDo: verify the paths to the jars. modify accordingly.
dependency_parser_config = {"name": "corenlp", "model": os.path.join(".", "examples","assets","jars","stanford-english-corenlp-2018-10-05-models.jar"),"parser": os.path.join(".", "examples","assets","jars","stanford-parser.jar")}
# using Stanford CoreNLPServer
# ToDo: verify the URL to the CoreNLPServer. modify accordingly.
# dependency_parser_config = {"name": "corenlp-server", "url": "http://localhost:9000"}
# using Spacy
# ToDo: ensure that the below spacy model is installed. if using another model, modify accordingly.
# dependency_parser_config = {"name": "spacy", "model": "en_core_web_sm", "parser": None}
# Set the Dependency Parser
nl4dv_instance.set_dependency_parser(config=dependency_parser_config)
# Define a query
query = "create a barchart showing average gross across genres"
# Execute the query
output = nl4dv_instance.analyze_query(query)
Applications
Follow these steps to run the example applications:
Download or Clone the repository using
git clone https://github.com/nl4dv/nl4dv.git-
cdinto the examples directory and create a new virtual environment.virtualenv --python=python3 venv -
Activate it using:
source venv/bin/activate(MacOSX/ Linux)venv\Scripts\activate.bat(Windows) -
Install dependencies.
python -m pip install -r requirements.txt -
Manually install nl4dv in this virtual environment using one of the above instructions.
Run
python app.py.-
Open your favorite browser and go to http://localhost:7001. You should see something like:
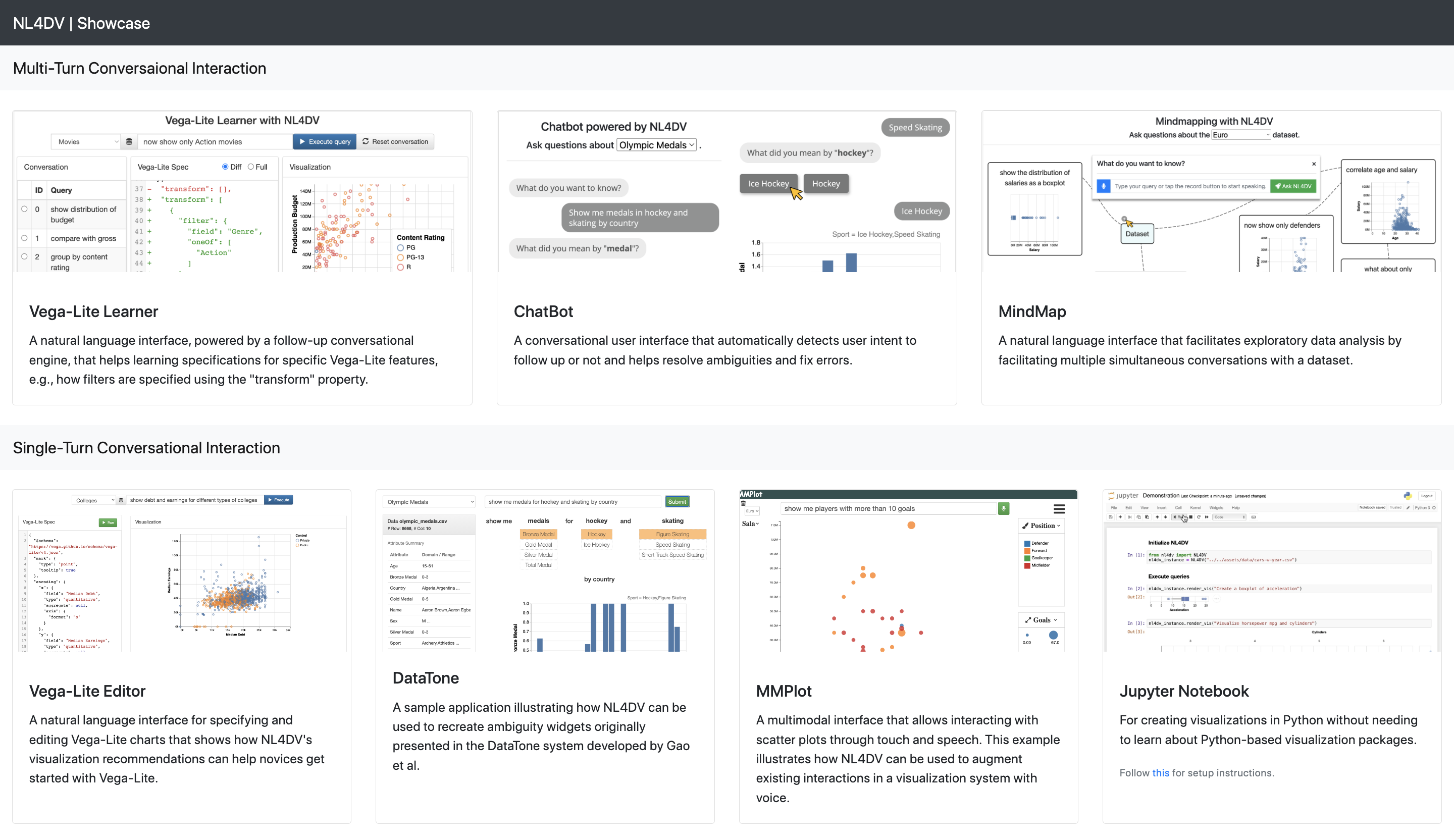
For the Jupyter Notebook application,
-
cdinto the examples directory. -
Install and enable the Vega extension in the notebook using
jupyter nbextension install --sys-prefix --py vegajupyter nbextension enable vega --py --sys-prefix
-
Launch the notebook using
jupyter notebook.Make sure your Jupyter notebook uses an (virtual) environment that has NL4DV installed. Go to examples/applications/notebook and launch Single-Turn-Conversational-Interaction.ipynb to run the demo that showcases NL4DV's single-turn (standalone) conversational capabilities or Multi-Turn-Conversational-Interaction.ipynb for viewing NL4DV's follow-up capabilities
API Reference
Common for v1, v2, v3, v4.
| Method | Params | Description |
|---|---|---|
| NL4DV() |
OR
|
NL4DV constructor. Returns:nl4dv_instance.
|
| nl4dv_instance.analyze_query() |
|
Analyzes the input query. Returns: a JSON object comprising detected attributes, inferred analytic tasks, and relevant visualizations. Note
The other properties in the output should be self-explanatory. Read the v1, v2, v3, v4 papers for details. |
| nl4dv_instance.render_vis() |
|
Calls analyze_query() internally, but... Returns: VegaLite() object of the best, most relevant visualization. This is useful to directly render a visualization in a Jupyter Notebook cell. |
| nl4dv_instance.set_data() |
OR
|
Sets the dataset to query against. Use this if you want to change the dataset after initializing the constructor. |
| nl4dv_instance.get_metadata() | - | Returns: a JSON object consisting of the dataset metadata (e.g., attributes and inferred data types, etc) that is set after NL4DV is initialized with a dataset. |
v4 (requires "processing_mode" set to "language-model")
| Method | Params | Description |
|---|---|---|
| NL4DV() |
Example (PDF | SVG): |
v3 (requires "processing_mode" set to "gpt")
| Method | Params | Description |
|---|---|---|
| NL4DV() |
|
v2 only (requires "processing_mode" set to "semantic-parsing")
| Method | Params | Description |
|---|---|---|
| NL4DV() |
|
|
| nl4dv_instance.analyze_query() |
|
dialog=True means a given query is a follow-up query; dialog=False means it is a new, standalone query; dialog='auto' means the user wants the system to automatically determine if the input query is a follow-up or not (and in which case you must not pass a dialog_id or a query_id). If a dialog_id and query_id are specified, then the user's intent is to follow-up on the specific query at the (dialog_id -> query_id) node in the conversation graph. Read the v2 paper to know more about dialog, dialog_id, and query_id. |
| nl4dv_instance.update_query() |
|
Resolve attribute-level and value-level ambiguities by setting the correct entities to the corresponding keywords (phrase) in the query. |
| nl4dv_instance.get_dialogs() |
|
Get a specific dialog (if dialog_id is provided), a specific query in a dialog (if both dialog_id and query_id are provided), or all dialogs (if none of dialog_id and query_id are provided). Returns the requested entities as JSON specifications. |
| nl4dv_instance.delete_dialogs(dialog_id=None, query_id=None) |
|
Delete a specific dialog (if dialog_id is provided), a specific query in a dialog (if both dialog_id and query_id are provided), or all dialogs (if none of dialog_id and query_id are provided), practically resetting the corresponding NL4DV instance. Returns the deleted entities as JSON specifications. |
| nl4dv_instance.undo() | Delete the most recently processed query; returns the deleted entity as a JSON specification. | |
| nl4dv_instance.set_explicit_followup_keywords() |
|
|
| nl4dv_instance.set_implicit_followup_keywords() |
|
v2 and v1 (requires "processing_mode" set to "semantic-parsing")
| Method | Params | Description |
|---|---|---|
| NL4DV() |
|
|
| nl4dv_instance.analyze_query() |
|
|
| nl4dv_instance.set_alias_map() |
OR
|
Sets the alias values. |
| nl4dv_instance.set_thresholds() |
|
Overrides the default thresholds such as string matching. |
| nl4dv_instance.set_importance_scores() |
|
Sets the Scoring Weights for the way attributes / tasks and visualizations are detected. |
| nl4dv_instance.set_attribute_datatype() |
|
Override the attribute datatypes that are detected by NL4DV. |
| nl4dv_instance.set_dependency_parser() |
|
Set the dependency parser to be used in the Tasks detector module. |
| nl4dv_instance.set_reserve_words() |
["A"]
# "A" - although an article (like 'a/an/the') should be retained in a grades dataset.
|
Set the custom STOPWORDS that should NOT be removed from the query, as they might be present in the domain. |
| nl4dv_instance.set_ignore_words() |
["movie"] |
Set the words that should be IGNORED in the query, i.e. NOT lead to the detection of attributes and tasks. |
| nl4dv_instance.set_label_attribute() |
["Model"]
# Correlate horsepower and MPG for sports car models" should NOT apply an explicit attribute for models since there are two explicit attributes already present.
|
Set the words that should be IGNORED in the query, i.e. NOT lead to the detection of attributes and tasks. |
FAQ | Message from Creators
As we plan additional features to add new features / improve the toolkit, we recommend users/developers to be aware of the following:
How is "data" returned in the output JSON?
If the data was input via the "data_value" parameter, to minimize the storage footprint of this output JSON, the Vega-Lite spec (vlSpec) will NOT include the dataset values (under the "data" > "value" property); you are expected to supply these to render the visualization. However, if the dataset was input via the "data_url" parameter, the 'vlSpec' will have this data configuration by default (under the "data" > "url" property).Dependency parser output variations.
The dependency tree returned by CoreNLP, CoreNLP Server, and Spacy are sometimes different. The current parser logic was developed for CoreNLP, hence it'll work best. However, we are upgrading the rules to work consistently across all dependency parsers.-
Attribute data types.
Verify the attribute types (e.g., nominal, temporal) that are detected by NL4DV and override them if they are incorrect as they will most likely lead to erroneous visualizations. The current attribute datatype detection logic is based on heuristics and we are currently working towards a major improvement that semantically infers the data type from both, the attribute's name and its value. -
Temporal attributes.
NL4DV relies on Regular Expressions to detect common date formats (listed in the order of priority in case of conflicts).Supported Date Formats (Codes: 1989 C standard) Examples %m*%d*%Yor%m*%d*%ywhere * ∈ {. - /}- 12.24.2019
- 12/24/2019
- 1-24-19
- 09.24.20
%Y*%m*%dor%y*%m*%dwhere * ∈ {. - /}- 2019.12.24
- 2019/12/24
- 19-1-24
- 20.09.24
%d*%m*%Yor%d*%m*%ywhere * ∈ {. - /}- 24.12.2019
- 24/12/2019
- 24-1-19
- 24.09.20
%d/%b/%Yor%d/%B/%Yor%d/%b/%yor%d/%B/%ywhere * ∈ {. - / space}- 8-January-2019
- 31 Dec 19
- 1/Jan/19
%d*%bor%d*%Bwhere * ∈ {. - / space}- 8-January
- 31 Dec
- 1/Jan
%b/%d/%Yor%B/%d/%Yor%b/%d/%yor%B/%d/%ywhere * ∈ {. - / space}- January-8-2019
- Dec 31 19
- Jan/1/19
%YOnly the following series: - 18XX (e.g., 1801)
- 19XX (e.g., 1929)
- 20XX (e.g., 2010)
Filter task.
NL4DV applies the filter task by matching the condition against each data point but does not encode the involved attributes in the visualization. This was a design decision taken to avoid recommending a complex visualization due to too many encoded attributes.Thresholds and Match scores.
These are currently set based on heuristics and prior research works; we encourage users/developers to modify them to suit their specific requirements.
Build
NL4DV can be installed as a Python package and imported in your own awesome applications!
-
NL4DV is written in Python 3. Please ensure you have a Python 3 environment already installed.
-
Clone this repository (master branch) and enter (`cd`) into it.
-
Create a new virtual environment.
virtualenv --python=python3 venv -
Activate it using:
source venv/bin/activate(MacOSX/ Linux)venv\Scripts\activate.bat(Windows) -
Install dependencies.
python -m pip install -r requirements.txt - make your changes>
-
Bump up the version in setup.py and create a Python distributable.
python setup.py sdist -
This will create a new file inside **nl4dv-*.*.*.tar.gz** inside the dist directory.
-
Install the above file in your Python environment using:
python -m pip install <PATH-TO-nl4dv-*.*.*.tar.gz> -
Verify by opening your Python console and importing it:
$python >>> from nl4dv import NL4DV - Enjoy, NL4DV is now available for use as a Python package!
Docker | only v1
NL4DV v1 is containerized into a Docker Image. This image comes pre-installed with NL4DV, Spacy, Stanford CoreNLP, and a few datasets with a web application as a Demo. Install it using:
docker pull arpitnarechania/nl4dvNote: This mode of installation does not require the Post Installation steps. For more informations, follow the detailed instructions in the Github repository (nl4dv-docker).
Credits
NL4DV is a collaborative project originally created by the Georgia Tech Visualization Lab at Georgia Institute of Technology with subsequent contributions from Ribarsky Center for Visual Analytics at UNC Charlotte and the DataVisards Group at The Hong Kong University of Science and Technology.
-
Georgia Tech Visualization Lab
- Arpit Narechania (currently at HKUST)
- Arjun Srinivasan
- Rishab Mitra
- Alex Endert
- John Stasko
-
Ribarsky Center for Visual Analytics at UNC Charlotte
-
DataVisards Group at The Hong Kong University of Science and Technology
- Arpit Narechania (previously at Georgia Tech)
-
Independent Contributor
- Tenghao Ji
We thank the members of the Georgia Tech Visualization Lab for their support and constructive feedback. We also thank @vijaynyaya for the inspiration to support multiple language model providers.
Citations
2025 (coming soon)
@misc{sah2024generatinganalyticspecificationsdata,
title={{NL4DV-Stylist: Styling Data Visualizations Using Natural Language and Example Charts}},
author={{Ji}, Tenghao and {Narechania}, Arpit},
year={2025}
}2024 IEEE VIS NLVIZ Workshop Track
@misc{sah2024generatinganalyticspecificationsdata,
title={Generating Analytic Specifications for Data Visualization from Natural Language Queries using Large Language Models},
author={{Sah}, Subham and {Mitra}, Rishab and {Narechania}, Arpit and {Endert}, Alex and {Stasko}, John and {Dou}, Wenwen},
year={2024},
eprint={2408.13391},
archivePrefix={arXiv},
primaryClass={cs.HC},
url={https://arxiv.org/abs/2408.13391},
howpublished = {Presented at NLVIZ Workshop, IEEE VIS 2024},
}2022 IEEE VIS Conference Short Paper Track
@inproceedings{mitra2022conversationalinteraction,
title = {Facilitating Conversational Interaction in Natural Language Interfaces for Visualization},
author = {{Mitra}, Rishab and {Narechania}, Arpit and {Endert}, Alex and {Stasko}, John},
booktitle={2022 IEEE Visualization Conference (VIS)},
url = {https://doi.org/10.48550/arXiv.2207.00189},
doi = {10.48550/arXiv.2207.00189},
year = {2022},
publisher = {IEEE}
}2021 IEEE TVCG Journal Full Paper (Proceedings of the 2020 IEEE VIS Conference)
@article{narechania2021nl4dv,
title = {{NL4DV}: A {Toolkit} for Generating {Analytic Specifications} for {Data Visualization} from {Natural Language} Queries},
shorttitle = {{NL4DV}},
author = {{Narechania}, Arpit and {Srinivasan}, Arjun and {Stasko}, John},
journal = {IEEE Transactions on Visualization and Computer Graphics},
doi = {10.1109/TVCG.2020.3030378},
year = {2021},
publisher = {IEEE}
}Contact Us
If you have any questions, feel free to open a GitHub issue or contact Arpit Narechania.
License
The software is available under the MIT License.